No single AI model is best at everything anymore, and the lineup changes every few weeks. The teams that win will not bet on one model and marry it. They will orchestrate, routing each task to the right model and the right agent, and let an orchestrator handle it. CRHQ is built for exactly that, from delegation that works out of the box to deep, custom routing you set up once.
No single model wins
The reflex is to find the one best model and standardize on it. That era is over. Right now the strengths are split:
- Sonnet 4.6 is the best value for writing, content, and most routine agentic work. It is often as good as Opus at writing, for a fraction of the cost.
- Opus 4.8 shines on complex reasoning and high-quality UI and design.
- Fable 5 is the new top tier for the hardest, longest, highest-value problems.
- GPT-5.5 via Codex is exceptionally good across most agentic work and still heavily subsidized through a subscription.
- Cursor Composer 2.5 delivers comparable quality at roughly 10x lower cost, ideal for high-volume work.
And the lineup keeps moving. Fable 5 just landed. xAI now owns Cursor's training data and is expected to ship a strong, very cheap model soon. Six months out, there will likely be an Opus-level model at about a dollar per million tokens. Standardizing your whole operation on one model is a bet you will keep losing.
The answer: orchestration
Instead of one model, you run an orchestrator agent that routes each task to the right model. One orchestrator can spin up many sub-agents, each running a different model, and combine their work. You teach the orchestrator once, and your team never has to think about which model to use.
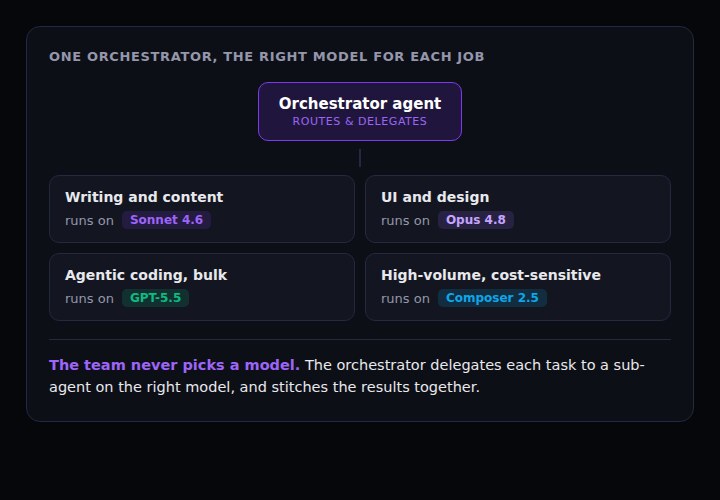
How CRHQ does this, built in
- Delegation, built in. Any agent can spin up and delegate to other agents out of the box. A project manager agent hands work to the right specialist with no setup, and each sub-agent can run on its own model.
- Deeper orchestration when you want it. Set up an orchestration agent with explicit routing rules: which agent and which model handles which kind of task. It routes between both agents and models, sending writing to a content agent on Sonnet, code to a dev agent on GPT-5.5, design to Opus.
- Three providers, many models, selectable anywhere. Claude (Sonnet, Opus, Fable, Haiku), OpenAI Codex (GPT-5.5, GPT-5.4), and Cursor (Composer 2.5). Choose a model per agent, per session, or per background job.
- Model-specialized agents. Give each agent a default model. Your content agent defaults to Sonnet, your UI agent to Opus, your orchestrator to GPT-5.5. The routing is baked in.
- Automatic cost tracking by model. CRHQ logs usage and cost per model, so you see exactly where the spend goes and route deliberately.
Know your costs, down to the turn
Orchestration only pays off if you can see what each model actually costs. CRHQ shows a full cost breakdown inside every session, under Session Details, then Costs. It tracks the equivalent token cost even when you run on a subscription, broken down by model and by turn, so the expensive habits are obvious at a glance.
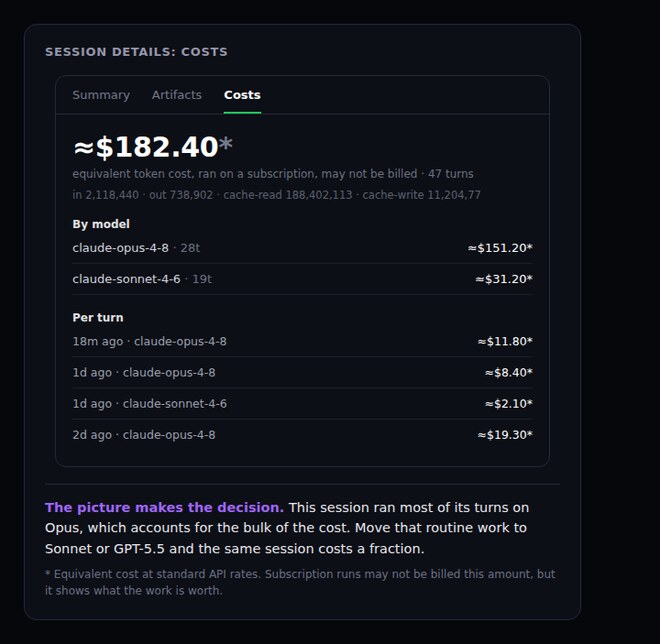
The picture makes the decision. A session that runs most of its turns on Opus will show Opus accounting for the bulk of the cost. Move that routine work to Sonnet or GPT-5.5 and the same session costs a fraction.
Test, then decide
Not sure which model is best for a task? Run the test in minutes. Spin up a project manager agent, instructed to run three sub-agents, each with a different model, give them the same brief, and compare the results side by side.
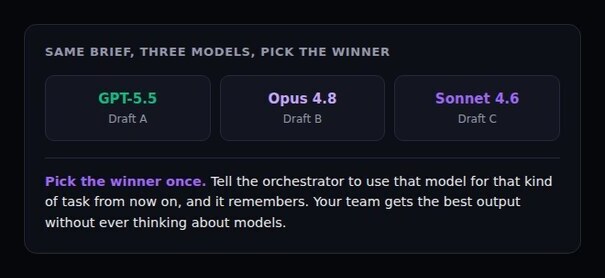
Pick the winner once. Tell the orchestrator to use that model for that kind of task from now on, and it remembers. Your team gets the best output without ever thinking about models.
Why this future-proofs you
When the next great model lands, and it will, every few weeks, you do not rewrite your skills, your prompts, or your agents. You point the orchestrator at the new model and keep going. Your workflows stay the same. Only the routing changes. That is the difference between scrambling every time the landscape shifts and simply absorbing it.
The spread is the opportunity
The gap between the cheapest and the most expensive model is roughly 20x. Routing the right task to the right model is where the savings live.
Where to start
- Give each agent a sensible default model so your everyday work already runs on the right one.
- Route routine and bulk work to cheaper models like GPT-5.5 (Codex) or Cursor Composer 2.5, and save the premium models for where they earn it.
- Set up an orchestrator that routes between your agents and models. Reach out and we will help you structure it.
Common questions
Do I have to pick one model?
No. CRHQ lets an orchestrator route each task to the right model automatically, so you get the best of each one without choosing.
How can one agent use multiple models?
Through delegation. An orchestrator agent spins up sub-agents and assigns each one a model, for example Sonnet for writing and GPT-5.5 for code, then combines the results.
What happens when a new model comes out?
You point your orchestrator at it. Your skills, prompts, and agents stay the same. Only the routing changes.
Will switching models break my skills and prompts?
Usually not, and the orchestrator abstracts the difference. The safe way to switch is to test models side by side on the same task and pick the winner.
The volatility is not going away. New models, new prices, every few weeks. The teams that thrive will not chase the best model. They will orchestrate the ones they have. CRHQ gives you that orchestration today.